General
Tip
To read the entire answer to a FAQ,
click the arrow icon (![]() ) below any question to
expand or collapse it.
) below any question to
expand or collapse it.
What is COPO?
Click to view answer
COPO standards for Collaborative OPen Omics. It is a web-based platform that helps the scientific community describe their research data using FAIR community standards and share it with appropriate public repositories. It is an open-source project based at the Earlham Institute (EI) formerly known as TGAC in Norwich, United Kingdom.
COPO simplifies the process of preparing, validating and submitting research metadata, making it easier for persons to comply with data sharing requirements and promote open science.
COPO supports a variety of data types, including genomic sequences, phenotypic data and ecological observations. It provides tools for metadata annotation, data validation and submission to repositories such as the European Nucleotide Archive (ENA), the Open Science Framework (OSF) and Dataverse among others.
What data types can be submitted?
Click to view answer
The Collaborative OPen Omics (COPO) project supports the following types of omics data:
Assemblies (e.g. FASTA)
Barcoding (e.g. 10x Genomics, PacBio)
Images (e.g. REMBI, ST-FISH)
Reads (e.g. Illumina, Oxford Nanopore Technologies, PacBio)
Samples (e.g. Tree of Life, DwC, MIxS, FAANG)
Sequence Annotations (e.g., GFF3, VCF)
Single-cell (e.g. 10x Genomics, Smart-seq)
In addition, COPO supports the submission of associated data files. See Uploading Data Files for more information.
How can I check the status of my data submissions?
Click to view answer
The Data status & progress shows the various stages of submission
processing. It is located at the right of the data table. Hover over the
![]() beside each stage to view the status description.
beside each stage to view the status description.
Please refer to the following sections for more information about viewing submission status for different data types:
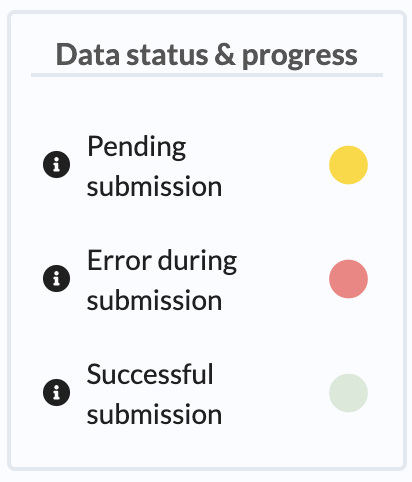
Data submission status and progress legend their corresponding label colours
Colour |
Status |
Description |
|---|---|---|
Yellow |
Pending submission |
Yellow highlight means that the data is not yet submitted and no accessions have been assigned. |
Red |
Error during submission |
Red highlight means that there was a problem with the data submission or the data requires attention before it can be successfully submitted. |
Green |
Successful submission |
Green highlight means that the data has been successfully submitted and no further action is needed. |



When was the COPO project launched?
Click to view answer
In September 2014, the COPO project was launched under the Biotechnology and Biological Sciences Research Council (BBSRC) with the aim of improving open access to and management of data within plant research. It was known as Collaborative Open Plant Omics at that time and is based at the The Genome Analysis Centre (TGAC).
Now, the project is known as Collaborative OPen Omics. It is based at the Earlham Institute (EI) formerly known as TGAC.
2014 - 2022 |
2023 - PRESENT |
|---|---|
|
|
|
See also
Download a seminar presentationwhich gives an overview of the evolution of the COPO project since its inception in 2014 to the present day
Who are the developers of the COPO project?
Click to view answer
Please see COPO team section on the About web page of the COPO’s website for current software developers of the project.
How can I contact the COPO team?
Click to view answer
You can contact the COPO team by sending an email to or by using the contact form on the Contact page of the COPO’s website.
Does COPO provide an API?
Click to view answer
Yes, COPO provides a RESTful API that allows programmatic access to its features and functionalities.
For more information, please refer to the Using COPO API documentation.
Is there a COPO testing website?
Click to view answer
Yes, COPO has a testing website that users can explore features and functionalities before performing actual submissions. It can be accessed at https://demo.copo-project.org.
Any data submitted via this testing site is not submitted to any public repositories and is deleted after 24 hours.